
Introduction
git clone git@github.com:Mathpix/api-examples.git
cd api-examples/images
MathpixOCR recognizes printed and handwritten STEM document content, including math, text, tables, and chemistry diagrams, from an image, stroke data, or a PDF file. The returned content for an image or stroke data may be Mathpix Markdown, LaTeX, AsciiMath, MathML, or HTML. For a PDF file the content is also available as docx.
This page describes the MathpixOCR requests and responses. If you have any questions or problems, please send email to support@mathpix.com.
Authorization
Using server side API keys
Include the following headers in every request:
{
"app_id": "APP_ID",
"app_key": "APP_KEY"
}
Every MathpixOCR server side request should include two headers: app_id to identify
your application and app_key to authorize access to the service.
You can find your API key on your account dashboard at
https://accounts.mathpix.com/ocr-api.
Note: never include your API keys inside client side code. Such API keys can easily be stolen by hackers by inspecting the app binary. If you want to make direct requests from client side code to the API, use app tokens, described below.
Using client side app tokens
To get a temporary
app_token, do the following:
curl -X POST https://api.mathpix.com/v3/app-tokens -H 'app_key: APP_KEY'
import requests
url = "https://api.mathpix.com/v3/app-tokens"
headers = {
"app_key": "APP_KEY"
}
response = requests.post(url, headers=headers)
print(response.json())
This then returns an
app_tokenvalue which can be used as anapp_tokenheader to authenticate requests:
{
"app_token": "token_e06840c31fbfd28c2aba38207e417c4e",
"app_token_expires_at": "1649699265744"
}
You can also create short lived client side tokens to make requests from clients (for example mobile apps) directly to Mathpix OCR servers. This reduces the need for customers to proxy their requests through their server to secure the requests. As such, it avoids an additional network hop, resulting in improved latency.
To get a temporary app token on your server to hand off to a client, use your API key to make a request to:
POST api.mathpix.com/v3/app-tokens
The app_token will last for 5 minutes, after which requests will return HTTP status 401 (unauthorized). In such
cases, the client can request an additional app token. Requests to create app tokens are free of charge.
With app_token, you only need a single authenticated route on your servers to get an app_token for your user.
This means you do not need to worry about proxying image requests to our servers.
We have designed app tokens for individual image and digital ink requests (strokes) only. As such, app tokens have the following limitations when compared to API keys:
- cannot access PDF functionality
- cannot access historical data
- cannot access account admin data
- cannot not make batch / async requests
Note: the app tokens feature is in beta and is being actively developed.
Request JSON parameters:
| Parameter | Type | Description |
|---|---|---|
| include_strokes_session_id (optional) | boolean | Return a strokes_session_id value that can be used for live update drawing, see v3/strokes for more info |
| expires (optional) | number (seconds) | Specifies how long the app_token will last. The Default is 300 seconds. Values can range from 30 - 43200 seconds (12 hours) for an app_token and from 30 - 300 seconds (5 minutes) for a request with include_strokes_session_id |
Response JSON parameters:
| Parameter | Type | Description |
|---|---|---|
| app_token | string | App token to be used in headers of v3/text, v3/latex, or v3/strokes requests |
| strokes_session_id (optional) | string | if requested via, include_strokes_session_id, you can use this value to take advantage of our live digital ink pricing and SDKs, see v3/strokes |
| app_token_expires_at | number (seconds) | Specifies when the app_token will expire in Unix time |
Process an image
Example image:
JSON request body to send an image URL:

{
"src": "https://mathpix-ocr-examples.s3.amazonaws.com/cases_hw.jpg",
"formats": ["text", "data"],
"data_options": {
"include_asciimath": true
}
}
Response:
{
"auto_rotate_confidence": 0.0046418966250847404,
"auto_rotate_degrees": 0,
"confidence": 0.9849104881286621,
"confidence_rate": 0.9849104881286621,
"data": [
{
"type": "asciimath",
"value": "f(x)={[x^(2),\" if \"x<0],[2x,\" if \"x>=0]:}"
}
],
"is_handwritten": true,
"is_printed": false,
"request_id": "eec691de4cad35bcf5cfad28d865278b",
"text": "\\( f(x)=\\left\\{\\begin{array}{ll}x^{2} & \\text { if } x<0 \\\\ 2 x & \\text { if } x \\geq 0\\end{array}\\right. \\)",
"version": "RSK-M100"
}
POST api.mathpix.com/v3/text
To process an image with MathpixOCR,
a client may post a form to v3/text containing the image file and
a single form field options_json specifying the desired options.
Alternatively,
a client may post a JSON body to v3/text
containing a link to the image in the src field along with
the desired options.
For backward compatibility a client also may post a JSON body containing
the base64 encoding of the image in the src field.
The response body is JSON containing the recognized content and
information about the recognition.
The text field contains Mathpix Markdown, including math as LaTeX
inside inline delimiters \( ... \) and block mode delimiters \[ .... \].
Chemistry diagrams are returned as <smiles>...</smiles>
where ... is the SMILES (simplified molecular-input line-entry system)
representation of chemistry diagrams.
Lines are separated with \n newline characters.
In some cases (e.g., multiple choice equations)
horizontally-aligned content will be flattened into different lines.
We also provide structured data results via the data and html options.
The data output returns a list of extracted formats
(such as tsv for tables, or asciimath for equations).
The html output provides annotated HTML compatible with HTML/XML parsers.
Request parameters
Example of sending an image URL:
#!/usr/bin/env python
import requests
import json
r = requests.post("https://api.mathpix.com/v3/text",
json={
"src": "https://mathpix-ocr-examples.s3.amazonaws.com/cases_hw.jpg",
"math_inline_delimiters": ["$", "$"],
"rm_spaces": True
},
headers={
"app_id": "APP_ID",
"app_key": "APP_KEY",
"Content-type": "application/json"
}
)
print(json.dumps(r.json(), indent=4, sort_keys=True))
curl -X POST https://api.mathpix.com/v3/text \
-H 'app_id: APP_ID' \
-H 'app_key: APP_KEY' \
-H 'Content-Type: application/json' \
--data '{"src": "https://mathpix-ocr-examples.s3.amazonaws.com/cases_hw.jpg", "math_inline_delimiters": ["$", "$"], "rm_spaces": true}'
Send an image file:
#!/usr/bin/env python
import requests
import json
r = requests.post("https://api.mathpix.com/v3/text",
files={"file": open("cases_hw.jpg","rb")},
data={
"options_json": json.dumps({
"math_inline_delimiters": ["$", "$"],
"rm_spaces": True
})
},
headers={
"app_id": "APP_ID",
"app_key": "APP_KEY"
}
)
print(json.dumps(r.json(), indent=4, sort_keys=True))
curl -X POST https://api.mathpix.com/v3/text \
-H 'app_id: APP_ID' \
-H 'app_key: APP_KEY' \
--form 'file=@"cases_hw.jpg"' \
--form 'options_json="{\"math_inline_delimiters\": [\"$\", \"$\"], \"rm_spaces\": true}"'
Response:
{
"auto_rotate_confidence": 0.0046418966250847404,
"auto_rotate_degrees": 0,
"confidence": 0.9849104881286621,
"confidence_rate": 0.9849104881286621,
"is_handwritten": true,
"is_printed": false,
"latex_styled": "f(x)=\\left\\{\\begin{array}{ll}\nx^{2} & \\text { if } x<0 \\\\\n2 x & \\text { if } x \\geq 0\n\\end{array}\\right.",
"request_id": "bd02af63ef187492c085331c60151d98",
"text": "$f(x)=\\left\\{\\begin{array}{ll}x^{2} & \\text { if } x<0 \\\\ 2 x & \\text { if } x \\geq 0\\end{array}\\right.$",
"version": "RSK-M100"
}
{
"src": "https://mathpix-ocr-examples.s3.amazonaws.com/cases_hw.jpg",
"formats": ["text", "data", "html"],
"data_options": {
"include_asciimath": true,
"include_latex": true
}
}
| Parameter | Type | Description |
|---|---|---|
| src (optional) | string | Image URL |
| metadata (optional) | object | Key-value object |
| tags (optional) | [string] | Tags are lists of strings that can be used to identify results. see query image results |
| async (optional) | [bool] | This flag is to be used when sending non-interactive requests |
| callback (optional) | object | Callback object |
| formats (optional) | [string] | List of formats, one of text, data, html, latex_styled, see Format Descriptions |
| data_options (optional) | object | See DataOptions section, specifies outputs for data and html return fields |
| include_detected_alphabets (optional) | bool | Return detected alphabets |
| alphabets_allowed (optional) | object | See AlphabetsAllowed section, use this to specify which alphabets you don't want in the output |
| region (optional) | object | Specify the image area with the pixel coordinates top_left_x, top_left_y, width, and height |
| enable_blue_hsv_filter (optional) | bool | Enables a special mode of image processing where it OCRs blue hue text exclusively, default false. |
| confidence_threshold (optional) | number in [0,1] | Specifies threshold for triggering confidence errors |
| confidence_rate_threshold (optional) | number in [0,1] | Specifies threshold for triggering confidence errors, default 0.75 (symbol level threshold) |
| include_line_data (optional) | bool | Specifies whether to return information segmented line by line, see LineData object section for details |
| include_word_data (optional) | bool | Specifies whether to return information segmented word by word, see WordData object section for details |
| include_smiles (optional) | bool | Enable experimental chemistry diagram OCR, via RDKIT normalized SMILES with isomericSmiles=False, included in text output format, via MMD SMILES syntax <smiles>...</smiles> |
| include_inchi (optional) | bool | Include InChI data as XML attributes inside <smiles> elements, for examples <smiles inchi="..." inchikey="...">...</smiles>; only applies when include_smiles is true |
| include_geometry_data (optional) | bool | Enable data extraction for geometry diagrams (currently only supports triangle diagrams); see GeometryData |
| auto_rotate_confidence_threshold (optional) | number in [0,1] | Specifies threshold for auto rotating image to correct orientation; by default it is set to 0.99, can be disabled with a value of 1 (see Auto rotation section for details) |
| rm_spaces (optional) | bool | Determines whether extra white space is removed from equations in latex_styled and text formats. Default is true. |
| rm_fonts (optional) | bool | Determines whether font commands such as \mathbf and \mathrm are removed from equations in latex_styled and text formats. Default is false. |
| idiomatic_eqn_arrays (optional) | bool | Specifies whether to use aligned, gathered, or cases instead of an array environment for a list of equations. Default is false. |
| idiomatic_braces (optional) | bool | Specifies whether to remove unnecessary braces for LaTeX output. When true, x^2 is returned instead of x^{2}. Default is false. |
| numbers_default_to_math (optional) | bool | Specifies whether numbers are always math, e.g., Answer: \( 17 \) instead of Answer: 17. Default is false. |
| math_inline_delimiters (optional) | [string, string] | Specifies begin inline math and end inline math delimiters for text outputs. Default is ["\\(", "\\)"]. |
| math_display_delimiters (optional) | [string, string] | Specifies begin display math and end display math delimiters for text outputs. Default is ["\\[", "\\]"]. |
| enable_spell_check | bool | Enables a predictive mode for English handwriting that takes word frequencies into account; this option is skipped when the language is not detected as English; incorrectly spelled words that are clearly written will not be changed, this predictive mode is only enabled when the underlying word is visually ambiguous, see here for an example. |
| enable_tables_fallback | bool | Enables advanced table processing algorithm that supports very large and complex tables. Defaults to false |
Format descriptions
MathpixOCR returns strings in one of the selected formats:
| Format | Description |
|---|---|
| text | Mathpix Markdown |
| html | HTML rendered from text via mathpix-markdown-it |
| data | Data computed from text as specified in the data_options request parameter |
| latex_styled | Styled Latex, returned only in cases that the whole image can be reduced to a single equation |
DataOptions object
Data options are used to return elements of the image output. These outputs are all computed from the text format described above.
| Key | Type | Description |
|---|---|---|
| include_svg (optional) | bool | include math SVG in html and data formats |
| include_table_html (optional) | bool | include HTML for html and data outputs (tables only) |
| include_latex (optional) | bool | include math mode latex in data and html |
| include_tsv (optional) | bool | include tab separated values (TSV) in data and html outputs (tables only) |
| include_asciimath (optional) | bool | include asciimath in data and html outputs |
| include_mathml (optional) | bool | include mathml in data and html outputs |
Response body
Get an API response:
{
"confidence": 0.9982182085336344,
"confidence_rate": 0.9982182085336344,
"is_printed": false,
"is_handwritten": true,
"data": [
{
"type": "asciimath",
"value": "lim_(x rarr3)((x^(2)+9)/(x-3))"
},
{
"type": "latex",
"value": "\\lim _{x \\rightarrow 3}\\left(\\frac{x^{2}+9}{x-3}\\right)"
}
],
"html": "<div><span class=\"math-inline \" >\n<asciimath style=\"display: none;\">lim_(x rarr3)((x^(2)+9)/(x-3))</asciimath><latex style=\"display: none\">\\lim _{x \\rightarrow 3}\\left(\\frac{x^{2}+9}{x-3}\\right)</latex></span></div>\n",
"text": "\\( \\lim _{x \\rightarrow 3}\\left(\\frac{x^{2}+9}{x-3}\\right) \\)"
}
| Field | Type | Description |
|---|---|---|
| request_id | string | Request ID, for debugging purposes |
| text (optional) | string | Recognized text format, if such is found |
| latex_styled (optional) | string | Math Latex string of math equation, if the image is of a single equation |
| confidence (optional) | number in [0,1] | Estimated probability 100% correct |
| confidence_rate (optional) | number in [0,1] | Estimated confidence of output quality |
| line_data (optional) | [object] | List of LineData objects |
| word_data (optional) | [object] | List of WordData objects |
| data (optional) | [object] | List of Data objects |
| html (optional) | string | Annotated HTML output |
| detected_alphabets (optional) | [object] | DetectedAlphabet object |
| is_printed (optional) | bool | Specifies if printed content was detected in an image |
| is_handwritten (optional) | bool | Specifies if handwritten content was detected in an image |
| auto_rotate_confidence (optional) | number in [0,1] | Estimated probability that image needs to be rotated, see Auto rotation |
| geometry_data (optional) | [object] | List of GeometryData objects |
| auto_rotate_degrees (optional) | number in {0, 90, -90, 180} | Estimated angle of rotation in degrees to put image in correct orientation, see Auto rotation |
| error (optional) | string | US locale error message |
| error_info (optional) | object | Error info object |
| version | string | This string is opaque to clients and only useful as a way of understanding differences in results for requests using the same image. Our service relies on training data, the service implementation, and the underlying platforms we run on (e.g., AWS, PyTorch). Initially, the version string will only change when the training data or process changes, but in the future we might provide additional distinctions between versions. |
Data object
Data objects allow extracting the math elements from an OCR result.
| Field | Type | Description |
|---|---|---|
| type | string | one of asciimath, mathml, latex, svg, tsv |
| value | string | value corresponding to type |
DetectedAlphabet object
The detected_alphabets object in a result contains a field that is true of false for each known alphabet. The field is true if any characters from the alphabet are recognized in the image, regardless of whether any of the result fields contain the characters.
| Field | Type | Description |
|---|---|---|
| en | bool | English |
| hi | bool | Hindi Devanagari |
| zh | bool | Chinese |
| ja | bool | Kana Hiragana or Katakana |
| ko | bool | Hangul Jamo |
| ru | bool | Russian |
| th | bool | Thai |
| ta | bool | Tamil |
| te | bool | Telugu |
| gu | bool | Gujarati |
| bn | bool | Bengali |
| vi | bool | Vietnamese |
AlphabetsAllowed object
{
"formats": ["text"],
"alphabets_allowed": {
"hi": false,
"zh": false,
"ja": false,
"ko": false,
"ru": false,
"th": false,
"ta": false,
"te": false,
"gu": false,
"bn": false,
"vi": false
}
}
There are cases where it is not easy to infer the correct alphabet for a single letter
because there are different letters from different alphabets that look alike. To illustrate, one example is conflict
between Latin B and Cyrillic В (that is Latin V). While being displayed almost the same, they essentially have
different Unicode encodings. The option alphabets_allowed can be used to specify map from string to boolean values
which can be used to prevent symbols from unwanted alphabet appearing in the result. Map keys that are valid correspond
to the values in Field column of the table specified in Detected alphabet object section (e.g. hi or ru). By
default all alphabets are allowed in the output, to disable alphabet specify "alphabets_allowed": {"alphabet_key": false}.
Specifying "alphabets_allowed": {"alphabet_key": true} has the same effect as not specifying that alphabet inside
alphabets_allowed map.
LineData object
Example request:
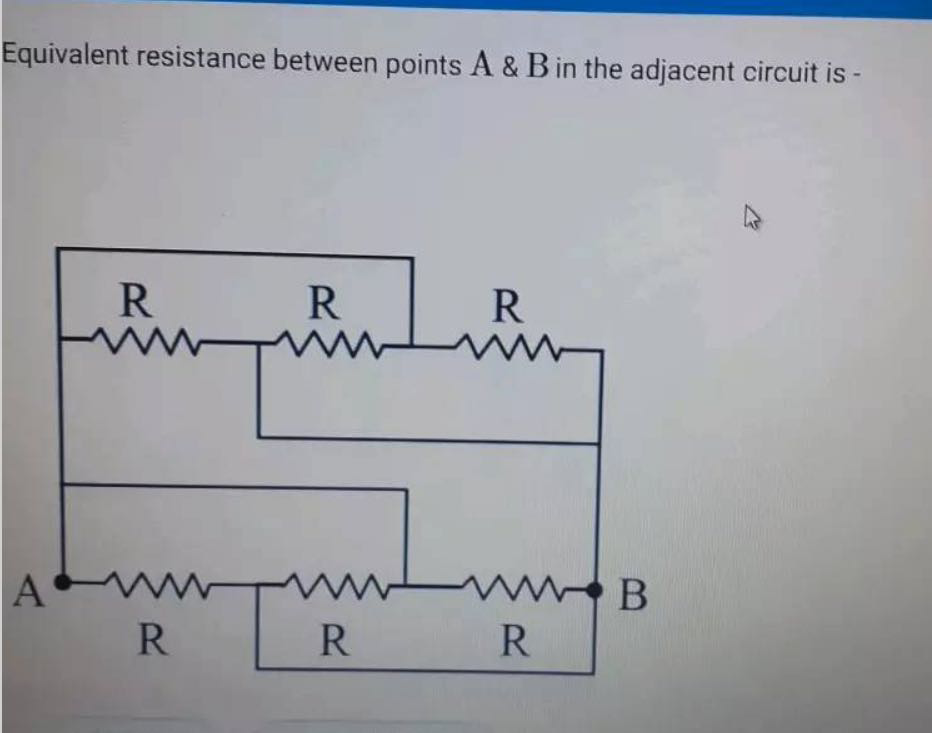
{
"src": "https://mathpix.com/examples/text_with_diagram.png",
"formats": ["text"],
"include_line_data": true
}
JSON response:
{
"confidence": 0.651358435330524,
"confidence_rate": 0.651358435330524,
"text": "Equivalent resistance between points \\( \\mathrm{A} \\& \\mathrm{B} \\) in the adjacent circuit is",
"line_data": [
{
"type": "text",
"cnt": [
[859, 81],
[739, 91],
[626, 91],
[-2, 66],
[0, 34],
[739, 52],
[859, 63]
],
"included": true,
"is_printed": true,
"is_handwritten": false,
"text": "Equivalent resistance between points \\( \\mathrm{A} \\& \\mathrm{B} \\) in the adjacent circuit is",
"after_hyphen": false,
"confidence": 0.651358435330524,
"confidence_rate": 0.9948483133235457
},
{
"type": "diagram",
"cnt": [
[654, 244],
[651, 683],
[7, 678],
[11, 238]
],
"included": false,
"is_printed": true,
"is_handwritten": false,
"error_id": "image_not_supported"
}
]
}
| Field | Type | Description |
|---|---|---|
| type | string | One of text, math, table, diagram, equation_number, diagram_info, chart, form_field |
| subtype (optional) | string | For diagrams: chemistry, triangle. For charts: column, bar, line, pie, area, scatter. For form fields: checkbox, circle, dashed. When not applicable, it is not set. |
| cnt | [[x,y]] | Contour for line expressed as list of (x,y) pixel coordinate pairs |
| included | bool | Whether this line is included in the top level OCR result |
| is_printed | bool | True if line has printed text, false otherwise. |
| is_handwritten | bool | True if line has handwritten text, false otherwise. |
| error_id (optional) | string | Error ID, reason why the line is not included in final result |
| text (optional) | string | Text (Mathpix Markdown) for line |
| confidence (optional) | number in [0,1] | Estimated probability 100% correct |
| confidence_rate (optional) | number in [0,1] | Estimated confidence of output quality |
| after_hyphen (optional) | bool | specifies if the current line occurs after the text line which ended with hyphen |
| html (optional) | string | Annotated HTML output for the line |
| data (optional) | [Data] | List of Data object's |
Specifying include_line_data to be true will add a line_data field
to the response body. This field is a list of LineData objects
that contain information about all textual line elements detected in the image.
Simply concatenating information from the response's line_data is enough
to recreate the top level text, html, and data fields in the response body.
The OCR engine does not support some lines, like diagrams, and
these lines are therefore simply skipped.
Some lines contain content that is most likely extraneous, like equation numbers.
Additionally, sometimes the OCR engine simply cannot recognize the line
with proper confidence. In all those cases included field is set to false,
meaning the line is not part of the final result.
A line can have the following values for error_id:
- image_not_supported - OCR engine doesn't accept this type of line
- image_max_size - line is larger than maximal size which OCR engine supports
- math_confidence - OCR engine failed to confidently recognize the content of the line
- image_no_content - line has strange spatial dimensions, e.g. height of the line is zero; this error is very unlikely to happen
WordData object
Example request:
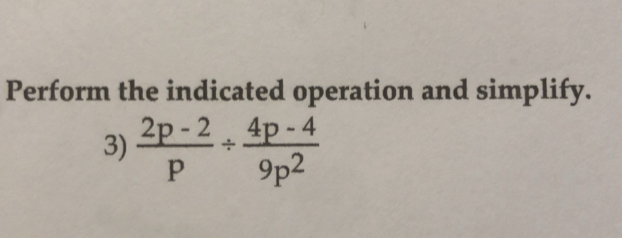
{
"src": "https://mathpix.com/examples/text_with_math_0.jpg",
"include_word_data": true
}
JSON response:
{
"is_printed": true,
"is_handwritten": false,
"auto_rotate_confidence": 0.00939574267408716,
"auto_rotate_degrees": 0,
"word_data": [
{
"type": "text",
"cnt": [
[111, 104],
[3, 104],
[3, 74],
[111, 74]
],
"text": "Perform",
"confidence": 0.99951171875,
"confidence_rate": 0.9999593007867263,
"latex": "\\text { Perform }"
},
{
"type": "text",
"cnt": [
[160, 104],
[115, 104],
[115, 74],
[160, 74]
],
"text": "the",
"confidence": 1,
"confidence_rate": 1,
"latex": "\\text { the }"
},
{
"type": "text",
"cnt": [
[286, 104],
[163, 104],
[163, 74],
[286, 74]
],
"text": "indicated",
"confidence": 0.9970722198486328,
"confidence_rate": 0.9997905880380586,
"latex": "\\text { indicated }"
},
{
"type": "text",
"cnt": [
[413, 107],
[290, 107],
[290, 77],
[413, 77]
],
"text": "operation",
"confidence": 0.9985356330871582,
"confidence_rate": 0.9998953311820248,
"latex": "\\text { operation }"
},
{
"type": "text",
"cnt": [
[469, 104],
[417, 104],
[417, 74],
[469, 74]
],
"text": "and",
"confidence": 1,
"confidence_rate": 1,
"latex": "\\text { and }"
},
{
"type": "text",
"cnt": [
[592, 108],
[472, 108],
[472, 74],
[592, 74]
],
"text": "simplify.",
"confidence": 0.9790234565734863,
"confidence_rate": 0.9984868832735626,
"latex": "\\text { simplify. }"
},
{
"type": "text",
"cnt": [
[126, 162],
[100, 162],
[100, 130],
[126, 130]
],
"text": "3)",
"confidence": 0.998046875,
"confidence_rate": 0.9997207483071853,
"latex": "\\text { 3) }"
},
{
"type": "math",
"cnt": [
[322, 191],
[132, 191],
[132, 110],
[322, 110]
],
"text": "\\( \\frac{2 p-2}{p} \\div \\frac{4 p-4}{9 p^{2}} \\)",
"confidence": 0.99853515625,
"confidence_rate": 0.9999436201400773,
"latex": "\\frac{2 p-2}{p} \\div \\frac{4 p-4}{9 p^{2}}"
}
]
}
| Field | Type | Description |
|---|---|---|
| type | string | One of text, math, table, diagram, equation_number |
| subtype (optional) | string | Either not set, or chemistry, or triangle (more diagram subtypes coming soon) |
| cnt | [[x,y]] | Contour for word expressed as list of (x,y) pixel coordinate pairs |
| text (optional) | string | Text (Mathpix Markdown) for word |
| latex (optional) | string | Math mode LaTeX (Mathpix Markdown) for word |
| confidence (optional) | number in [0,1] | Estimated probability 100% correct |
| confidence_rate (optional) | number in [0,1] | Estimated confidence of output quality |
Specifying true for include_word_data will add a word_data field
to the response body. This field is a a list of WordData objects
containing information about all word level elements detected in the image.
Auto rotation
Sometimes images that are received are in wrong orientation,one example of such image would look like this:
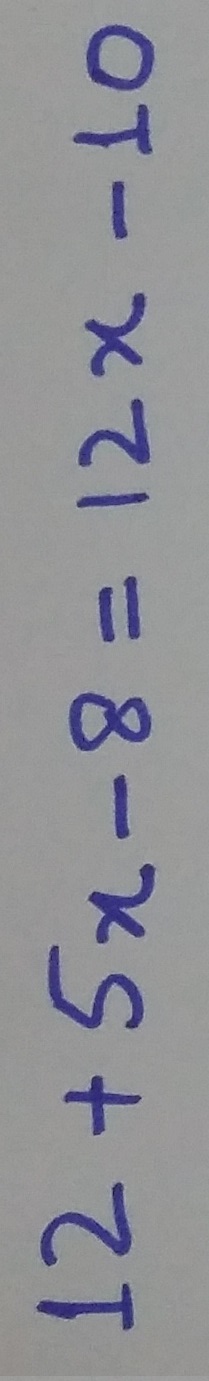
The goal of automatic rotation is to pick correct orientation for received images before any processing is done. The result of auto rotation looks like:
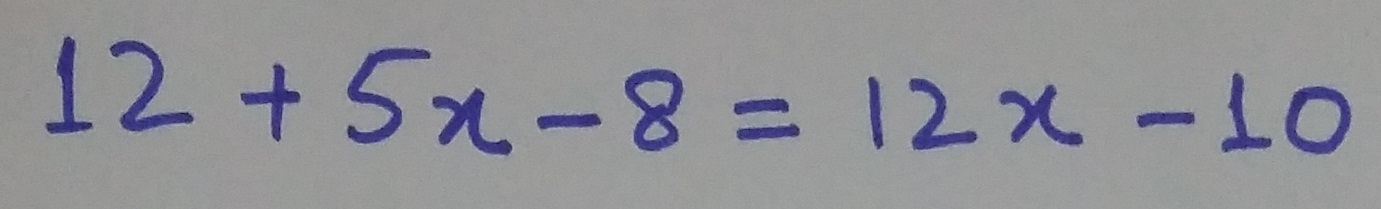
One can control how confident our algorithm needs to be to perform auto rotation with request parameter auto_rotate_confidence_threshold, a number in [0,1]. By default the value 0.99 is used, which essentially means that algorithm will auto rotate image if it is 99% confident in that decision. Auto rotation can be disabled by specifying "auto_rotate_confidence_threshold": 1 as a part of request being sent.
The response body will include two related fields:
auto_rotate_confidence- confidence of the algorithm in decision that image needs to be rotated, number in [0,1] which should be ~0 if image is in correct orientation and ~1 if image should be rotated; monitoring this value on custom workloads can be helpful in determining properauto_rotate_confidence_thresholdto be used with such workloadsauto_rotate_degrees- angle in degrees specifying how much to rotate original image to get image in proper orientation, number in {0, 90, -90, 180}, value 0 means image is already in correct orientation; this information can be used to put image in right orientation for other parts of image processing
Geometry objects
Example request to v3/text:
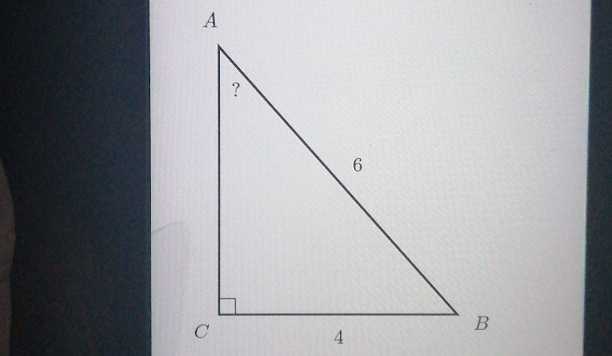
{
"src": "https://mathpix.com/examples/triangle_0.jpg",
"include_geometry_data": true
}
JSON response:
{
"is_printed": true,
"is_handwritten": false,
"auto_rotate_confidence": 0.03240217728347261,
"auto_rotate_degrees": 0,
"geometry_data": [
{
"position": {
"top_left_x": 183,
"top_left_y": 3,
"height": 344,
"width": 309
},
"shape_list": [
{
"type": "triangle",
"vertex_list": [
{
"x": 218,
"y": 46,
"edge_list": [1, 2]
},
{
"x": 218,
"y": 314,
"edge_list": [0, 2]
},
{
"x": 456,
"y": 314,
"edge_list": [0, 1]
}
]
}
],
"label_list": [
{
"position": {
"top_left_x": 198,
"top_left_y": 7,
"height": 24,
"width": 22
},
"text": "\\( A \\)",
"latex": "A",
"confidence": 0.99951171875,
"confidence_rate": 0.99951171875
},
{
"position": {
"top_left_x": 228,
"top_left_y": 78,
"height": 20,
"width": 14
},
"text": "\\( ? \\)",
"latex": "?",
"confidence": 0.96923828125,
"confidence_rate": 0.96923828125
},
{
"position": {
"top_left_x": 349,
"top_left_y": 154,
"height": 21,
"width": 16
},
"text": "6",
"latex": "6",
"confidence": 0.99951171875,
"confidence_rate": 0.99951171875
},
{
"position": {
"top_left_x": 189,
"top_left_y": 318,
"height": 24,
"width": 23
},
"text": "\\( C \\)",
"latex": "C",
"confidence": 0.837890625,
"confidence_rate": 0.837890625
},
{
"position": {
"top_left_x": 329,
"top_left_y": 326,
"height": 20,
"width": 18
},
"text": "4",
"latex": "4",
"confidence": 1,
"confidence_rate": 1
},
{
"position": {
"top_left_x": 469,
"top_left_y": 311,
"height": 22,
"width": 22
},
"text": "\\( B \\)",
"latex": "B",
"confidence": 0.99072265625,
"confidence_rate": 0.99072265625
}
]
}
]
}
Geometry data is requested via the include_geometry_data request parameter. Currently, only triangle diagrams are supported. Geometry data structures are represented via vertices, edges, and labels.
GeometryData object
The geometry_data object contains the following parameters:
| Field | Type | Description |
|---|---|---|
| position (optional) | object | Position object, pixel coordinates |
| shape_list | [object] | List of ShapeData objects |
| label_list | [object] | List of LabelData objects |
ShapeData object
| Field | Type | Description |
|---|---|---|
| type | string | Type of diagram; currently only triangle is supported |
| vertex_list | [object] | List of VertexData objects |
VertexData object
| Field | Type | Description |
|---|---|---|
| x | integer | x-pixel coordinate for the vertex, counting from top left |
| y | integer | y-pixel coordinate for the vertex, counting from top left |
| edge_list | [integer] | List of indices the vertex is connected to, in ShapeData.vertex_list (0 based indexing is used) |
LabelData object
| Field | Type | Description |
|---|---|---|
| position | object | Position object, pixel coordinates |
| text | string | text output for OCR-ed label |
| latex | string | latex output for OCR-ed label |
| confidence (optional) | number in [0,1] | Estimated probability 100% correct |
| confidence_rate (optional) | number in [0,1] | Estimated confidence of output quality |
Process stroke data
POST api.mathpix.com/v3/strokes
To process strokes coordinates, a client may post a JSON body to v3/strokes containing the strokes data along with the same options available when processing an image.
This endpoint is very convenient for users that were generating images of handwritten math and text and then using the service v3/text, since with v3/strokes no image generation is required, the request payload is smaller and therefore it results in faster response time.
The LaTeX of the recognized handwriting is returned inside inline delimiters \( ... \) and block mode delimiters \[ .... \]. Lines are separated with \n newline characters. In some cases (e.g. multiple choice equations) we will try to flatten horizontally aligned content into different lines in order to keep the markup simple.
Request parameters
Send some strokes:
{
"strokes": {
"strokes": {
"x": [
[
131, 131, 130, 130, 131, 133, 136, 146, 151, 158, 161, 162, 162, 162,
162, 159, 155, 147, 142, 137, 136, 138, 143, 160, 171, 190, 197, 202,
202, 202, 201, 194, 189, 177, 170, 158, 153, 150, 148
],
[231, 231, 233, 235, 239, 248, 252, 260, 264, 273, 277, 280, 282, 283],
[
273, 272, 271, 270, 267, 262, 257, 249, 243, 240, 237, 235, 234, 234,
233, 233
],
[
296, 296, 297, 299, 300, 301, 301, 302, 303, 304, 305, 306, 306, 305,
304, 298, 294, 286, 283, 281, 281, 282, 284, 284, 285, 287, 290, 293,
294, 299, 301, 308, 309, 314, 315, 316
]
],
"y": [
[
213, 213, 212, 211, 210, 208, 207, 206, 206, 209, 212, 217, 220, 227,
230, 234, 236, 238, 239, 239, 239, 239, 239, 239, 241, 247, 252, 259,
261, 264, 266, 269, 270, 271, 271, 271, 270, 269, 268
],
[231, 231, 232, 235, 238, 246, 249, 257, 261, 267, 270, 272, 273, 274],
[
230, 230, 230, 231, 234, 240, 246, 258, 268, 273, 277, 281, 281, 283,
283, 284
],
[
192, 192, 191, 189, 188, 187, 187, 187, 188, 188, 190, 193, 195, 198,
200, 205, 208, 213, 215, 215, 215, 214, 214, 214, 214, 216, 218, 220,
221, 223, 223, 223, 223, 221, 221, 220
]
]
}
}
}
#!/usr/bin/env python
import requests
import json
# put input strokes here
strokes_string = '{"strokes": {\
"x": [[131,131,130,130,131,133,136,146,151,158,161,162,162,162,162,159,155,147,142,137,136,138,143,160,171,190,197,202,202,202,201,194,189,177,170,158,153,150,148],[231,231,233,235,239,248,252,260,264,273,277,280,282,283],[273,272,271,270,267,262,257,249,243,240,237,235,234,234,233,233],[296,296,297,299,300,301,301,302,303,304,305,306,306,305,304,298,294,286,283,281,281,282,284,284,285,287,290,293,294,299,301,308,309,314,315,316]],\
"y": [[213,213,212,211,210,208,207,206,206,209,212,217,220,227,230,234,236,238,239,239,239,239,239,239,241,247,252,259,261,264,266,269,270,271,271,271,270,269,268],[231,231,232,235,238,246,249,257,261,267,270,272,273,274],[230,230,230,231,234,240,246,258,268,273,277,281,281,283,283,284],[192,192,191,189,188,187,187,187,188,188,190,193,195,198,200,205,208,213,215,215,215,214,214,214,214,216,218,220,221,223,223,223,223,221,221,220]]\
}}'
strokes = json.loads(strokes_string)
r = requests.post("https://api.mathpix.com/v3/strokes",
json={"strokes": strokes},
headers={"app_id": "APP_ID", "app_key": "APP_KEY",
"Content-type": "application/json"})
print(json.dumps(r.json(), indent=4, sort_keys=True))
curl -X POST https://api.mathpix.com/v3/strokes \
-H 'app_id: APP_ID' \
-H 'app_key: APP_KEY' \
-H 'Content-Type: application/json' \
--data '{ "strokes": {"strokes": {
"x": [[131,131,130,130,131,133,136,146,151,158,161,162,162,162,162,159,155,147,142,137,136,138,143,160,171,190,197,202,202,202,201,194,189,177,170,158,153,150,148],[231,231,233,235,239,248,252,260,264,273,277,280,282,283],[273,272,271,270,267,262,257,249,243,240,237,235,234,234,233,233],[296,296,297,299,300,301,301,302,303,304,305,306,306,305,304,298,294,286,283,281,281,282,284,284,285,287,290,293,294,299,301,308,309,314,315,316]],
"y": [[213,213,212,211,210,208,207,206,206,209,212,217,220,227,230,234,236,238,239,239,239,239,239,239,241,247,252,259,261,264,266,269,270,271,271,271,270,269,268],[231,231,232,235,238,246,249,257,261,267,270,272,273,274],[230,230,230,231,234,240,246,258,268,273,277,281,281,283,283,284],[192,192,191,189,188,187,187,187,188,188,190,193,195,198,200,205,208,213,215,215,215,214,214,214,214,216,218,220,221,223,223,223,223,221,221,220]]
}}}'
| Parameter | Type | Description |
|---|---|---|
| strokes | JSON | Strokes in JSON with appropriate format |
| strokes_session_id (optional) | string | Stroke session ID returned included by app token API call |
All other Request Params from v3/text are supported, See Request parameters.
Note that the strokes_session* information but be sent along with the app_token token as a auth header, see app tokens. Strokes sessions, meaning digital ink inputs with live updating results, are billed differently from v3/strokes requests without intermediate results (no live updates), see the Mathpix OCR pricing section. Note that customers are billed for a live strokes session the first time they send strokes for a given session, not when they request app_token and strokes_session_id.
Response body
Get an API response:
{
"request_id": "cea6b8e40ab4550ac467ce2eb00430be",
"is_printed": false,
"is_handwritten": true,
"auto_rotate_confidence": 0.0020149118193977245,
"auto_rotate_degrees": 0,
"confidence": 1,
"confidence_rate": 1,
"latex_styled": "3 x^{2}",
"text": "\\( 3 x^{2} \\)",
"version": "RSK-M100"
}
| Field | Type | Description |
|---|---|---|
| text (optional) | string | Recognized text format, if such is found |
| confidence (optional) | number in [0,1] | Estimated probability 100% correct |
| confidence_rate (optional) | number in [0,1] | Estimated confidence of output quality |
| data (optional) | [object] | List of data objects (see "Data object" section above) |
| html (optional) | string | Annotated HTML output |
Process an equation image
Example image:
JSON request body to send an image URL:

{
"src": "https://mathpix-ocr-examples.s3.amazonaws.com/limit.jpg",
"formats": ["latex_normal"]
}
Response:
{
"auto_rotate_confidence": 0.0006091455863810324,
"auto_rotate_degrees": 0,
"detection_list": [],
"detection_map": {
"contains_chart": 0,
"contains_diagram": 0,
"contains_graph": 0,
"contains_table": 0,
"is_blank": 0,
"is_inverted": 0,
"is_not_math": 0,
"is_printed": 5.874842099728994e-5
},
"latex_confidence": 1,
"latex_confidence_rate": 1,
"latex_normal": "\\operatorname { lim } _ { x \\rightarrow 3 } ( \\frac { x ^ { 2 } + 9 } { x - 3 } )",
"position": {
"height": 263,
"top_left_x": 59,
"top_left_y": 25,
"width": 578
},
"request_id": "85c5aa804c0db262ec806967acba0999",
"version": "RSK-M100"
}
POST api.mathpix.com/v3/latex
Legacy endpoint for processing equation image. Deprecated in favor of v3/text.
Request parameters
Example request sending an image URL:
#!/usr/bin/env python
import requests
import json
data = {
"src": "https://mathpix-ocr-examples.s3.amazonaws.com/limit.jpg",
"formats": [
"latex_simplified",
"asciimath"
]
}
r = requests.post("https://api.mathpix.com/v3/latex",
json=data,
headers={
"app_id": "APP_ID",
"app_key": "APP_KEY",
"Content-type": "application/json"
}
)
print(json.dumps(r.json(), indent=4, sort_keys=True))
curl -X POST https://api.mathpix.com/v3/latex \
-H 'app_id: APP_ID' \
-H 'app_key: APP_KEY' \
-H 'Content-Type: application/json' \
--data '{"src": "https://mathpix-ocr-examples.s3.amazonaws.com/limit.jpg", "formats": ["latex_simplified", "asciimath"]}'
Send an image file:
#!/usr/bin/env python
import requests
import json
r = requests.post("https://api.mathpix.com/v3/latex",
files={"file": open("limit.jpg","rb")},
data={"options_json": json.dumps({
"formats": ["latex_simplified", "asciimath"]
})},
headers={
"app_id": "APP_ID",
"app_key": "APP_KEY"
}
)
print(json.dumps(r.json(), indent=4, sort_keys=True))
curl -X POST https://api.mathpix.com/v3/latex \
-H 'app_id: APP_ID' \
-H 'app_key: APP_KEY' \
--form 'file=@"limit.jpg"' \
--form 'options_json="{\"formats\": [\"latex_simplified\", \"asciimath\"]}"'
{
"asciimath": "lim_(x rarr3)((x^(2)+9)/(x-3))",
"auto_rotate_confidence": 0.0006091455863810324,
"auto_rotate_degrees": 0,
"detection_list": [],
"detection_map": {
"contains_chart": 0,
"contains_diagram": 0,
"contains_graph": 0,
"contains_table": 0,
"is_blank": 0,
"is_inverted": 0,
"is_not_math": 0,
"is_printed": 5.874842099728994e-5
},
"latex_confidence": 1,
"latex_confidence_rate": 1,
"latex_simplified": "\\lim _ { x \\rightarrow 3 } ( \\frac { x ^ { 2 } + 9 } { x - 3 } )",
"position": {
"height": 263,
"top_left_x": 59,
"top_left_y": 25,
"width": 578
},
"request_id": "aab527abf5c78bd3a07c51804bcfbfaa",
"version": "RSK-M100"
}
You can request multiple formats for a single image:
{
"ocr": ["math", "text"],
"skip_recrop": true,
"formats": [
"text",
"latex_simplified",
"latex_styled",
"mathml",
"asciimath",
"latex_list"
]
}
| Parameter | Type | Description |
|---|---|---|
| src (optional) | string | Image URL |
| tags (optional) | [string] | Tags are lists of strings that can be used to identify results. see OCR Results |
| async (optional) | [bool] | This flag is to be used when sending non-interactive requests |
| formats | string[] | String postprocessing formats (see Formatting section) |
| ocr (optional) | string[] | Process only math ["math"] or both math and text ["math", "text"]. Default is ["math"] |
| format_options (optional) | object | Options for specific formats (see Formatting section) |
| skip_recrop (optional) | bool | Force algorithm to consider whole image |
| confidence_threshold (optional) | number in [0,1] | Set threshold for triggering confidence errors |
| beam_size (optional) | number in [1,5] | Number of results to consider during recognition |
| n_best (optional) | integer in [1,beam_size] | Number of highest-confidence results to return |
| region (optional) | object | Specify the image area with the pixel coordinates top_left_x, top_left_y, width, and height |
| callback (optional) | object | Callback object |
| metadata (optional) | object | Key value object |
| include_detected_alphabets (optional) | bool | Return detected alphabets |
| auto_rotate_confidence_threshold (optional) | number in [0,1] | Specifies threshold for auto rotating image to correct orientation; by default it is set to 0.99, can be disabled with a value of 1 (see Auto rotation section for details) |
| enable_blue_hsv_filter (optional) | bool | Enables a special mode of image processing where it OCRs blue hue text exclusively, default false. |
Formatting
The following formats can be used in the request:
| Format | Description |
|---|---|
| text | text mode output, with math inside delimiters, eg. test \(x^2\), inline math by default |
| text_display | same as text, except uses block mode math instead of inline mode when in doubt |
| latex_normal | direct LaTeX representation of the input |
| latex_styled | modified output to improve the visual appearance such as adding '\left' and '\right' around parenthesized expressions that contain tall expressions like subscript or superscript |
| latex_simplified | modified output for symbolic processing such as shortening operator names, replacing long division with a fraction, and converting a column of operands into a single formula |
| latex_list | output split into a list of simplified strings to help process multiple equations |
| mathml | the MathML for the recognized math |
| asciimath | the AsciiMath for the recognized math |
| wolfram | a string compatible with the Wolfram Alpha engine |
Format options
To return a more compact
latex_styledresult, one could send the following request:
{
"ocr": ["math", "text"],
"skip_recrop": true,
"formats": [
"text",
"latex_simplified",
"latex_styled",
"mathml",
"asciimath",
"latex_list"
],
"format_options": {
"latex_styled": { "transforms": ["rm_spaces"] }
}
}
The result for "latex*styled" would now be
>"\\lim*{x \\rightarrow 3}\\left(\\frac{x^{2}+9}{x-3}\\right)"
instead of
>"\\lim \_ { x \\rightarrow 3 } \\left( \\frac { x ^ { 2 } + 9 } { x - 3 } \\right)"
The optional format_options request parameter allows a request to customize the LaTeX result formats using an object with a format as the property name and the options for that format as the value. The options value may specify the following properties:
| Option | Type | Description |
|---|---|---|
| transforms | string[] | array of transformation names |
| math_delims | [string, string] | [begin, end] delimiters for math mode, for example \( and \) |
| displaymath_delims | [string, string] | [begin, end] delimiters for displaymath mode, for example \[ and \] |
The currently-supported transforms are:
| Transform | Description |
|---|---|
| rm_spaces | omit spaces around LaTeX groups and other places where spaces are superfluous |
| rm_newlines | uses spaces instead of newlines between text lines in paragraphs |
| rm_fonts | omit mathbb, mathbf, mathcal, and mathrm commands |
| rm_style_syms | replace styled commands with unstyled versions, e.g., bigoplus becomes oplus |
| rm_text | omit text to the left or right of math |
| long_frac | convert longdiv to frac |
Note that rm_fonts and rm_style_syms are implicit in latex_normal, latex_simplified, and latex_list. The long_frac transformation is implicit in latex_simplified and latex_list.
Response body
{
"detection_list": [],
"detection_map": {
"contains_chart": 0,
"contains_diagram": 0,
"contains_geometry": 0,
"contains_graph": 0,
"contains_table": 0,
"is_inverted": 0,
"is_not_math": 0,
"is_printed": 0
},
"latex_normal": "\\lim _ { x \\rightarrow 3 } ( \\frac { x ^ { 2 } + 9 } { x - 3 } )",
"latex_confidence": 0.86757309488734,
"latex_confidence_rate": 0.9875550770759583,
"position": {
"height": 273,
"top_left_x": 57,
"top_left_y": 14,
"width": 605
}
}
| Field | Type | Description |
|---|---|---|
| text (optional) | string | Recognized text format |
| text_display (optional) | string | Recognized text_display format |
| latex_normal (optional) | string | Recognized latex_normal format |
| latex_simplified (optional) | string | Recognized latex_normal format |
| latex_styled (optional) | string | Recognized latex_styled format |
| latex_list (optional) | string[] | Recognized latex_list format |
| mathml (optional) | string | Recognized MathML format |
| asciimath (optional) | string | Recognized AsciiMath format |
| wolfram (optional) | string | Recognized Wolfram format |
| position (optional) | object | Position object, pixel coordinates |
| detection_list (optional) | string[] | Detects image properties (see image properties) |
| error (optional) | string | US locale error message |
| error_info (optional) | object | Error info object |
| latex_confidence (optional) | number in [0,1] | Estimated probability 100% correct |
| latex_confidence_rate (optional) | number in [0,1] | Estimated confidence of output quality |
| candidates (optional) | object[] | n_best results |
| detected_alphabets (optional) | [object] | DetectedAlphabet object |
| auto_rotate_confidence (optional) | number in [0,1] | Estimated probability that image needs to be rotated, see Auto rotation |
| auto_rotate_degrees (optional) | number in {0, 90, -90, 180} | Estimated angle of rotation in degrees to put image in correct orientation, see Auto rotation |
The detected_alphabets result object contains a field that is true of false
for each known alphabet. The field is true if any characters from the alphabet
are recognized in the image, regardless of whether any of
the result fields contain the characters.
| Field | Type | Description |
|---|---|---|
| en | bool | English |
| hi | bool | Hindi Devenagari |
| zh | bool | Chinese |
| ja | bool | Kana Hiragana or Katakana |
| ko | bool | Hangul Jamo |
| ru | bool | Russian |
| th | bool | Thai |
| ta | bool | Tamil |
| te | bool | Telugu |
| gu | bool | Gujarati |
| bn | bool | Bengali |
Image properties
The API defines multiple detection types:
| Detection | Definition |
|---|---|
| contains_diagram | Contains a diagram. |
| is_printed | The image is taken of printed math, not handwritten math. |
| is_not_math | No valid equation was detected. |
Query image results
GET api.mathpix.com/v3/ocr-results
Mathpix allows customers to search their results from posts to /v3/text, /v3/strokes, and /v3/latex with a GET request on /v3/ocr-results?search-parameters.
The search request must also be authenticated the same way OCR requests are, in order to return relevant search results. See Authorization
Requests with the metadata improve_mathpix field set to false will not appear in the search results.
Note that this endpoint will only work with API keys created after July 5th, 2020.
Request parameters
curl -X GET -H 'app_key: APP_KEY' \
'https://api.mathpix.com/v3/ocr-results?from_date=2021-07-02T18%3A48%3A25.769285%2B00%3A00&page=1&per_page=10&tags=test_tag2&tags=test_tag3&is_handwritten=True'
{
"ocr_results": [
{
"timestamp": "2021-07-02T18:48:46.080Z",
"duration": 0.132,
"endpoint": "/v3/text",
"request_args": {
"tags": ["test_tag2", "test_tag3"],
"formats": ["text"]
},
"result": {
"text": "\\( 12+5 x-8=12 x-10 \\)",
"confidence": 1,
"is_printed": false,
"request_id": "a4301400f66b9821d35cbabea8a26992",
"is_handwritten": true,
"confidence_rate": 1,
"auto_rotate_degrees": 0,
"auto_rotate_confidence": 0.0027393347044402105,
"version": "RSK-M100"
},
"detections": {
"contains_chemistry": false,
"contains_diagram": false,
"is_handwritten": true,
"is_printed": false,
"contains_table": false,
"contains_triangle": false
}
},
{
"timestamp": "2021-07-02T18:48:45.903Z",
"duration": 0.15,
"endpoint": "/v3/text",
"request_args": {
"tags": ["test_tag", "test_tag2", "test_tag3"],
"formats": ["text"]
},
"result": {
"text": "\\( 12+5 x-8=12 x-10 \\)",
"confidence": 1,
"is_printed": false,
"request_id": "7fe48fb1cd61f8a00ba4e71381740efb",
"is_handwritten": true,
"confidence_rate": 1,
"auto_rotate_degrees": 0,
"auto_rotate_confidence": 0.0027393347044402105,
"version": "RSK-M100"
},
"detections": {
"contains_chemistry": false,
"contains_diagram": false,
"is_handwritten": true,
"is_printed": false,
"contains_table": false,
"contains_triangle": false
}
}
]
}
| Search parameter | Type | Description |
|---|---|---|
| page (default=1) | integer | First page of results to return |
| per_page (default=100) | integer | Number of results to return |
| from_date (optional) | string | starting (included) ISO datetime |
| to_date (optional) | string | ending (excluded) ISO datetime |
| app_id (optional) | string | results for the given app_id |
| text (optional) | string | result.text contains the given string |
| text_display (optional) | string | result.text_display contains the given string |
| latex_styled (optional) | string | result.latex_styled contains the given string |
| tags (optional) | [string] | an array of tag strings |
| is_printed (optional) | boolean | All results that contain printed text/math are included |
| is_handwritten (optional) | boolean | All results that contain handwritten text/math are included |
| contains_table (optional) | boolean | All results that contain a table are included |
| contains_chemistry (optional) | boolean | All results that contain chemistry diagrams are included |
| contains_diagram (optional) | boolean | All results that contain diagrams are included |
| contains_triangle (optional) | boolean | All results that contain triangles are included |
Result object
| Field | Type | Description |
|---|---|---|
| timestamp | string | ISO timestamp of recorded result information |
| endpoint | string | API endpoint used for upload (eg /v3/text, /v3/strokes, ...) |
| duration | number | Difference between timestamp and when request was received |
| request_args | object | Request body arguments |
| result | object | Result body for request |
| detections | object | An object of detections for each request |
Query ocr usage
GET api.mathpix.com/v3/ocr-usage
To track ocr usage, a user may get information from v3/ocr-usage, adding to the request period of time, and can group responses in different ways.
Request parameters
curl -X 'GET' \
'https://api.mathpix.com/v3/ocr-usage?from_date=2021-01-01T00%3A00%3A00.000Z&to_date=2021-01-02T00%3A00%3A00.000Z&group_by=usage_type×pan=month' \
-H 'app_id: APP_ID' \
-H 'app_key: APP_KEY'
| Search parameter | Type | Description |
|---|---|---|
| from_date (optional) | string | starting (included) ISO datetime |
| to_date (optional) | string | ending (excluded) ISO datetime |
| group_by | string | return values aggregated by this parameter. One of usage_type, request_args_hash, app_id |
| timespan | string | return aggregated by specified timespan |
Response body
Get an API response:
{
"ocr_usage": [
{
"from_date": "2022-01-01T00:00:00.000Z",
"app_id": ["mathpix"],
"usage_type": "image",
"request_args_hash": ["1f241a3777a5646b98eb4e07c1e39f27770c14d8"],
"count": 21
},
{
"from_date": "2022-01-01T00:00:00.000Z",
"app_id": ["mathpix"],
"usage_type": "image-async",
"request_args_hash": [
"05d8e589e40f0e071908e93facd5b3f4a3ec87c0",
"1402ecaace7d72c61a900f1f1e0d4c729db636e7"
],
"count": 7
}
]
}
| Field | Type | Description |
|---|---|---|
| from_date | string | starting (included) ISO datetime |
| usage_type | string | type of service |
| request_args_hash | string | hash of request_args |
| count | number | number of requests according to the selected group_by request parameter |
Process a PDF
POST api.mathpix.com/v3/pdf
Mathpix supports PDF processing for scientific documents.
Supported outputs:
- mmd file (Mathpix Markdown spec)
- md file (Markdown spec)
- DOCX file (compatible with MS Office, Google Docs, Libre Office)
- LaTeX zip file (includes images)
- HTML (rendered Mathpix Markdown content)
Request parameters
Send a PDF URL for processing:
#!/usr/bin/env python
import requests
import json
r = requests.post("https://api.mathpix.com/v3/pdf",
json={
"url": "http://cs229.stanford.edu/notes2020spring/cs229-notes1.pdf"
"conversion_formats": {
"docx": true,
"tex.zip": true
}
},
headers={
"app_id": "APP_ID",
"app_key": "APP_KEY",
"Content-type": "application/json"
}
)
print(json.dumps(r.json(), indent=4, sort_keys=True))
curl -X POST https://api.mathpix.com/v3/pdf \
-H 'app_id: APP_ID' \
-H 'app_key: APP_KEY' \
-H 'Content-Type: application/json' \
--data '{ "url": "http://cs229.stanford.edu/notes2020spring/cs229-notes1.pdf", "conversion_formats": {"docx": true, "tex.zip": true}}'
You can either send a PDF URL, or you can upload a file.
| Parameter | Type | Description |
|---|---|---|
| url (optional) | string | HTTP URL where PDF can be downloaded from |
| metadata (optional) | object | Key value object |
| alphabets_allowed (optional) | object | See AlphabetsAllowed section, use this to specify which alphabets you don't want in the output |
| rm_spaces (optional) | bool | Determines whether extra white space is removed from equations in latex_styled and text formats. Default is true. |
| rm_fonts (optional) | bool | Determines whether font commands such as \mathbf and \mathrm are removed from equations in latex_styled and text formats. Default is false. |
| idiomatic_eqn_arrays (optional) | bool | Specifies whether to use aligned, gathered, or cases instead of an array environment for a list of equations. Default is false. |
| include_equation_tags (optional) | bool | Specifies whether to include equation number tags inside equations LaTeX in the form of \tag{eq_number}, where eq_number is an equation number (e.g. 1.12). When set to true, it sets "idiomatic_eqn_arrays": true, because equation numbering works better in those environments compared to the array environment. |
| numbers_default_to_math (optional) | bool | Specifies whether numbers are always math, e.g., Answer: \( 17 \) instead of Answer: 17. Default is false. |
| math_inline_delimiters (optional) | [string, string] | Specifies begin inline math and end inline math delimiters for text outputs. Default is ["\\(", "\\)"]. |
| math_display_delimiters (optional) | [string, string] | Specifies begin display math and end display math delimiters for text outputs. Default is ["\\[", "\\]"]. |
| page_ranges | string | Specifies a page range as a comma-separated string. Examples include 2,4-6 which selects pages [2,4,5,6] and 2 - -2 which selects all pages starting with the second page and ending with the next-to-last page (specified by -2) |
| enable_spell_check | bool | Enables a predictive mode for English handwriting that takes word frequencies into account; this option is skipped when the language is not detected as English; incorrectly spelled words that are clearly written will not be changed, this predictive mode is only enabled when the underlying word is visually ambiguous, see here for an example. |
| auto_number_sections | bool | Specifies whether sections and subsections in the output are automatically numbered. Defaults to false note. |
| remove_section_numbering | bool | Specifies whether to remove existing numbering for sections and subsections. Defaults to false note. |
| preserve_section_numbering | bool | Specifies whether to keep existing section numbering as is. Defaults to true note. |
| enable_tables_fallback | bool | Enables advanced table processing algorithm that supports very large and complex tables. Defaults to false |
| conversion_formats | object | Specifies formats that the v3/pdf output(Mathpix Markdown) should automatically be converted into, on completion. See Conversion Formats. |
Send a PDF file for processing:
import requests
import json
options = {
"conversion_formats": {"docx": True, "tex.zip": True},
"math_inline_delimiters": ["$", "$"],
"rm_spaces": True
}
r = requests.post("https://api.mathpix.com/v3/pdf",
headers={
"app_id": "APP_ID",
"app_key": "APP_KEY"
},
data={
"options_json": json.dumps(options)
},
files={
"file": open("css299-notes.pdf","rb")
}
)
print(r.text.encode("utf8"))
curl --location --request POST 'https://api.mathpix.com/v3/pdf' \
--header 'app_id: APP_ID' \
--header 'app_key: APP_KEY' \
--form 'file=@"cs229-notes5.pdf"' \
--form 'options_json="{\"conversion_formats\": {\"docx\": true, \"tex.zip\": true}, \"math_inline_delimiters\": [\"$\", \"$\"], \"rm_spaces\": true}"'
To send a PDF file simply include the file in the form-data request body.
Response body
Reponse to PDF / PDF URL upload
{
"pdf_id": "5049b56d6cf916e713be03206f306f1a"
}
| Field | Type | Description |
|---|---|---|
| pdf_id | string | Tracking ID to get status and result when completed |
| error (optional) | string | US locale error message |
| error_info (optional) | object | Error info object |
Processing status
curl --location --request GET 'https://api.mathpix.com/v3/pdf/PDF_ID' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID'
Response after a few seconds:
{
"status": "split",
"num_pages": 9,
"percent_done": 11.11111111111111,
"num_pages_completed": 1
}
Response after a few more seconds:
{
"status": "completed",
"num_pages": 9,
"percent_done": 100,
"num_pages_completed": 9
}
To check the processing status of a PDF, use the pdf_id returned
from the initial request and append it to /v3/pdf in a GET request.
GET https://api.mathpix.com/v3/pdf/<PDF_ID>
| Field | Type | Description |
|---|---|---|
| status | string | Processing status, will be received upon successful request, loaded if PDF was down-loaded onto our servers, split when PDF pages are split and sent for processing, completed when PDF is done processing, or error if a problem occurs during processing |
| num_pages (optional) | integer | Total number of pages in PDF document |
| num_pages_completed (optional) | integer | Current number of pages in PDF document that have been OCR-ed |
| percent_done (optional) | number | Percentage of pages in PDF that have been OCR-ed |
Get conversion status
curl --location --request GET 'https://api.mathpix.com/v3/converter/PDF_ID' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID'
Response after a few seconds:
{
"status": "completed",
"conversion_status": {
"docx": {
"status": "processing"
},
"tex.zip": {
"status": "processing"
}
}
Response after a few more seconds:
{
"status": "completed",
"conversion_status": {
"docx": {
"status": "completed"
},
"tex.zip": {
"status": "completed"
}
}
To get the status of your conversions, use the following endpoint:
GET https://api.mathpix.com/v3/converter/<PDF_ID>
The response object is described here:
| Field | Type | Description |
|---|---|---|
| status | string | completed for an existing mmd document |
| conversion_status (optional) | object | {[format]: {status: "processing" | "completed" | "error", error_info?: {id, error}}} |
Conversion results
Save results to local mmd file, md file, docx file, HTML, and LaTeX zip
curl --location --request GET 'https://api.mathpix.com/v3/pdf/PDF_ID.mmd' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > PDF_ID.mmd
curl --location --request GET 'https://api.mathpix.com/v3/pdf/PDF_ID.docx' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > PDF_ID.docx
curl --location --request GET 'https://api.mathpix.com/v3/pdf/PDF_ID.tex' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > PDF_ID.tex.zip
curl --location --request GET 'https://api.mathpix.com/v3/pdf/PDF_ID.html' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > PDF_ID.html
curl --location --request GET 'https://api.mathpix.com/v3/pdf/PDF_ID.lines.json' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > PDF_ID.lines.json
curl --location --request GET 'https://api.mathpix.com/v3/pdf/PDF_ID.lines.mmd.json' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > PDF_ID.lines.mmd.json
import requests
pdf_id = "PDF_ID"
headers = {
"app_key": "APP_KEY",
"app_id": "APP_ID"
}
# get mmd response
url = "https://api.mathpix.com/v3/pdf/" + pdf_id + ".mmd"
response = requests.get(url, headers=headers)
with open(pdf_id + ".mmd", "w") as f:
f.write(response.text)
# get docx response
url = "https://api.mathpix.com/v3/pdf/" + pdf_id + ".docx"
response = requests.get(url, headers=headers)
with open(pdf_id + ".docx", "wb") as f:
f.write(response.content)
# get LaTeX zip file
url = "https://api.mathpix.com/v3/pdf/" + pdf_id + ".tex"
response = requests.get(url, headers=headers)
with open(pdf_id + ".tex.zip", "wb") as f:
f.write(response.content)
# get HTML file
url = "https://api.mathpix.com/v3/pdf/" + pdf_id + ".html"
response = requests.get(url, headers=headers)
with open(pdf_id + ".html", "wb") as f:
f.write(response.content)
# get lines data
url = "https://api.mathpix.com/v3/pdf/" + pdf_id + ".lines.json"
response = requests.get(url, headers=headers)
with open(pdf_id + ".lines.json", "wb") as f:
f.write(response.content)
# get lines mmd json
url = "https://api.mathpix.com/v3/pdf/" + pdf_id + ".lines.mmd.json"
response = requests.get(url, headers=headers)
with open(pdf_id + ".lines.mmd.json", "wb") as f:
f.write(response.content)
Once a PDF has been fully OCR-ed, resulting in status=completed,
you can get the mmd result and line-by-line data by adding .mmd or .lines.json
to the status GET request. Conversion formats such as docx and tex.zip
will not be available until the format status is completed.
The possible values of the extension are described here.
| Extension | Description |
|---|---|
| mmd | Returns Mathpix Markdown text file |
| md | Returns plain Markdown text file |
| docx | Returns a docx file |
| tex.zip | Returns a LaTeX zip file |
| html | Returns a HTML file with the rendered Mathpix Markdown content |
| lines.json | Returns line by line data |
| lines.mmd.json | Returns line by line mmd data |
Note that the tex.zip extension downloads a zip file containing the main .tex file and any images that appear in the document.
PDF lines data
To get line by line data with geometric information about PDF content:
curl --location --request GET 'https://api.mathpix.com/v3/pdf/PDF_ID.lines.json' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > PDF_ID.lines.json
import requests
pdf_id = "PDF_ID"
headers = {
"app_key": "APP_KEY",
"app_id": "APP_ID"
}
# get json lines data
url = "https://api.mathpix.com/v3/pdf/" + pdf_id + ".lines.json"
response = requests.get(url, headers=headers)
with open(pdf_id + ".lines.json", "w") as f:
f.write(response.text)
Response:
{
"pages": [
{
"image_id": "2022_04_27_feb905cbae93e99c93ecg-01",
"page": 1,
"page_height": 1651,
"page_width": 1275,
"lines": [
{
"cnt": [
[448, 395],
[448, 351],
[818, 351],
[818, 395]
],
"text": "CS229 Lecture Notes",
"is_printed": true,
"is_handwritten": false,
"region": {
"top_left_x": 448,
"top_left_y": 351,
"height": 45,
"width": 371
},
"line": 1
},
{
"cnt": [
[554, 469],
[554, 434],
[712, 434],
[712, 469]
],
"text": "Andrew Ng",
"is_printed": true,
"is_handwritten": false,
"region": {
"top_left_x": 554,
"top_left_y": 434,
"height": 36,
"width": 159
},
"line": 2
},
{
"cnt": [
[476, 537],
[476, 492],
[795, 492],
[795, 537]
],
"text": "(updates by Tengyu Ma)",
"is_printed": true,
"is_handwritten": false,
"region": {
"top_left_x": 476,
"top_left_y": 492,
"height": 46,
"width": 320
},
"line": 3
}
]
}
]
}
Mathpix provides detailed line by line data for PDFs. This can be useful for building novel user experiences on top of original PDFs.
Response data object
| Field | Type | Description |
|---|---|---|
| pages | PdfPageData | List of PdfPageData objects |
PdfPageData object
| Field | Type | Description |
|---|---|---|
| image-id | string | PDF ID, plus hyphen, plus page number, starting at page 1 |
| page | integer | Page number |
| lines | PdfLineData | List of LineData objects |
| page_height | integer | Page height (in pixel coordinates) |
| page_width | integer | Page width (in pixel coordinates) |
PdfLineData object
| Field | Type | Description |
|---|---|---|
| line | integer | Line number |
| text | string | Mathpix Markdown content |
| is_printed | boolean | True if line contains printed text, false otherwise. |
| is_handwritten | boolean | True if line contains handwritten text, false otherwise. |
| region | object | Specify the image area with the pixel coordinates top_left_x, top_left_y, width, and height |
| cnt | [[x,y]] | Specifies the image area as list of (x,y) pixel coordinate pairs. This captures handwritten content much better than a region object |
PDF MMD lines data
To get line by line data containing geometric and contextual information from a PDF:
curl --location --request GET 'https://api.mathpix.com/v3/pdf/PDF_ID.lines.mmd.json' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > PDF_ID.lines.mmd.json
import requests
pdf_id = "PDF_ID"
headers = {
"app_key": "APP_KEY",
"app_id": "APP_ID"
}
# get json lines data
url = "https://api.mathpix.com/v3/pdf/" + pdf_id + ".lines.mmd.json"
response = requests.get(url, headers=headers)
with open(pdf_id + ".lines.mmd.json", "w") as f:
f.write(response.text)
Response:
{
"pages": [
{
"image_id": "2022_04_27_5bd0e5ee1dbf53cc68c1g-1",
"page": 1,
"page_height": 1651,
"page_width": 1275,
"lines": [
{
"cnt": [
[448, 395],
[448, 351],
[818, 351],
[818, 395]
],
"region": {
"top_left_x": 448,
"top_left_y": 351,
"height": 45,
"width": 371
},
"is_printed": true,
"is_handwritten": false,
"text": "\\title{\nCS229 Lecture Notes\n}",
"line": 1
},
{
"cnt": [
[554, 469],
[554, 434],
[712, 434],
[712, 469]
],
"region": {
"top_left_x": 554,
"top_left_y": 434,
"height": 36,
"width": 159
},
"is_printed": true,
"is_handwritten": false,
"text": "\n\n\\author{\nAndrew Ng",
"line": 2
},
{
"cnt": [
[476, 537],
[476, 492],
[795, 492],
[795, 537]
],
"region": {
"top_left_x": 476,
"top_left_y": 492,
"height": 46,
"width": 320
},
"is_printed": true,
"is_handwritten": false,
"text": " \\\\ (updates by Tengyu Ma)\n}",
"line": 3
}
]
}
]
}
The MMD Lines object is much richer in context and lets you recreate the full MMD Document by simply appending the text fields in the PdfMMDLineData object.
Response data object (MMD Lines)
| Field | Type | Description |
|---|---|---|
| pages | PdfMMDPageData | List of PdfMMDPageData objects |
PdfMMDPageData object
| Field | Type | Description |
|---|---|---|
| image-id | string | PDF ID, plus hyphen, plus page number, starting at page 1 |
| page | integer | Page number |
| lines | PdfMMDLineData | List of PageMMDLineData objects |
| page_height | integer | Page height (in pixel coordinates) |
| page_width | integer | Page width (in pixel coordinates) |
PdfMMDLineData object
| Field | Type | Description |
|---|---|---|
| line | integer | Line number |
| text | string | Mathpix Markdown content with additional contextual elements such as article, section and inline image URLs |
| is_printed | boolean | True if line contains printed text, false otherwise. |
| is_handwritten | boolean | True if line contains handwritten text, false otherwise. |
| region | object | Specify the image area with the pixel coordinates top_left_x, top_left_y, width, and height |
| cnt | [[x,y]] | Specifies the image area as list of (x,y) pixel coordinate pairs. This captures handwritten content much better than a region object |
Deleting PDF results
To delete a PDF's data, use the DELETE method on the same URL as used for getting status or a document. When a PDF is deleted, the result MMD file and associated images and JSON lines data get deleted from our servers. The PDF status is unaffected.
Deleting a PDF that hasn't completed processing will return a 404. Only PDFs that have status=complete can be deleted.
Convert Documents
POST api.mathpix.com/v3/converter
If you want to convert an MMD document to other formats, you can do a POST to the /v3/converter endpoint with the mmd text and desired formats.
The available conversion formats are:
mddocxtex.ziphtml
Request parameters
Send an MMD document for conversion:
curl -X POST https://api.mathpix.com/v3/converter \
-H 'app_id: APP_ID' \
-H 'app_key: APP_KEY' \
-H 'Content-Type: application/json' \
--data '{ "mmd": "_full mmd text_", "formats": {"docx": true, "tex.zip": true}}'
import requests
import json
url = "https://api.mathpix.com/v3/converter"
payload = json.dumps({
"mmd": "_full mmd text_",
"formats": {
"docx": True,
"tex.zip": True
}
})
headers = {
'app_id': 'APP_ID',
'app_key': 'APP_KEY',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.json())
| Parameter | Type | Description |
|---|---|---|
| mmd | string | MMD document that needs to be converted into other formats |
| formats | object | Specifies output formats. See Conversion Formats. |
Response body
Reponse to a POST v3/converter request
{
"conversion_id": "5049b56d6cf916e713be03206f306f1a"
}
The result is just like a PDF request except returning conversion_id
instead of pdf_id. You use the conversion_id in a GET
to /v3/converter/conversion_id.
Conversion Formats
{
"md": false,
"docx": false,
"tex.zip": true,
"html": true
}
Conversion formats used for v3/pdf conversion_formats and v3/converter formats.
Get conversion status
curl --location --request GET 'https://api.mathpix.com/v3/converter/CONVERSION_ID' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID'
Response after a few seconds:
{
"status": "completed",
"conversion_status": {
"docx": {
"status": "processing"
},
"tex.zip": {
"status": "processing"
}
}
Response after a few more seconds:
{
"status": "completed",
"conversion_status": {
"docx": {
"status": "completed"
},
"tex.zip": {
"status": "completed"
}
}
To get the status of your conversions, use the following endpoint:
GET https://api.mathpix.com/v3/converter/<CONVERSION_ID>
The response object is described here:
| Field | Type | Description |
|---|---|---|
| status | string | completed for an existing mmd document |
| conversion_status (optional) | object | {[format]: {status: "processing" | "completed" | "error", error_info?: {id, error}}} |
Conversion results
Save results to local MD file, DOCX file, HTML, and LaTeX zip
curl --location --request GET 'https://api.mathpix.com/v3/converter/CONVERSION_ID.md' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > CONVERSION_ID.md
curl --location --request GET 'https://api.mathpix.com/v3/converter/CONVERSION_ID.docx' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > CONVERSION_ID.docx
curl --location --request GET 'https://api.mathpix.com/v3/converter/CONVERSION_ID.tex.zip' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > CONVERSION_ID.tex.zip
curl --location --request GET 'https://api.mathpix.com/v3/converter/CONVERSION_ID.html' \
--header 'app_key: APP_KEY' \
--header 'app_id: APP_ID' > CONVERSION_ID.html
import requests
conversion_id = "CONVERSION_ID"
headers = {
"app_key": "APP_KEY",
"app_id": "APP_ID"
}
# get md response
url = "https://api.mathpix.com/v3/converter/" + conversion_id + ".md"
response = requests.get(url, headers=headers)
with open(conversion_id + ".md", "w") as f:
f.write(response.text)
# get docx response
url = "https://api.mathpix.com/v3/converter/" + conversion_id + ".docx"
response = requests.get(url, headers=headers)
with open(conversion_id + ".docx", "wb") as f:
f.write(response.content)
# get LaTeX zip file
url = "https://api.mathpix.com/v3/converter/" + conversion_id + ".tex.zip"
response = requests.get(url, headers=headers)
with open(conversion_id + ".tex.zip", "wb") as f:
f.write(response.content)
# get HTML file
url = "https://api.mathpix.com/v3/converter/" + conversion_id + ".html"
response = requests.get(url, headers=headers)
with open(conversion_id + ".html", "wb") as f:
f.write(response.content)
Once the format status is completed you can download the content
by adding the format extension to the conversion_id, e.g.,
GET /v3/converter/conversion_id.docx.
| Extension | Description |
|---|---|
| md | Returns plain Markdown text file |
| docx | Returns a docx file |
| tex.zip | Returns a LaTeX zip file |
| html | Returns a HTML file with the rendered Mathpix Markdown content |
Note that the tex.zip extension downloads a zip file containing the main .tex file and any images that appear in the document.
Query PDF results
Mathpix allows customers to search their results from posts to /v3/pdf with a GET request on /v3/pdf-results?search-parameters. The search request must contain a valid app_key header to identify the group owning the results to search.
Request parameters
curl -X GET -H 'app_key: APP_KEY' \
'https://api.mathpix.com/v3/pdf-results?per_page=100&from_date=2020-06-26T03%3A08%3A22.827Z'
| Query parameter | Type | Description |
|---|---|---|
| page (default=1) | integer | First page of results to return |
| per_page (default=100) | integer | Number of results to return |
| from_date (optional) | string | starting (included) ISO datetime |
| to_date (optional) | string | ending (excluded) ISO datetime |
| app_id (optional) | string | results for the given app_id |
Query result object
{
"pdfs": [
{
"id": "113cee229ab27b715b7cc24cfdbb2c33",
"input_file": "https://s3.amazonaws.com/mathpix-ocr-examples/authors_0.pdf",
"status": "completed",
"created_at": "2020-06-26T03:08:23.827Z",
"modified_at": "2020-06-26T03:08:27.827Z",
"num_pages": 1,
"num_pages_completed": 1,
"request_args": {}
},
{
"id": "9ad69e94346e65047215d25709760f29",
"input_file": "https://s3.amazonaws.com/mathpix-ocr-examples/1457.pdf",
"status": "completed",
"created_at": "2020-06-27T03:08:23.827Z",
"modified_at": "2020-06-27T03:08:27.827Z",
"num_pages": 1,
"num_pages_completed": 1,
"request_args": {}
}
]
}
| Field | Type | Description |
|---|---|---|
| id | string | ID of the processed PDF |
| input_file | string | The URL or the filename of the processed PDF |
| created_at | string | ISO timestamp of when the PDF was received |
| modified_at | string | ISO timestamp of when the PDF finished processing |
| num_pages | integer | Number of pages in the request PDF |
| num_pages_completed | integer | Number of pages of the PDF that were processed |
| request_args | object | Request body arguments |
Process a batch
An equation image batch request is made with JSON that looks like:
{
"urls": {
"inverted": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/inverted.jpg",
"algebra": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/algebra.jpg"
},
"formats": ["latex_simplified"]
}
curl -X POST https://api.mathpix.com/v3/batch \
-H "app_id: APP_ID" \
-H "app_key: APP_KEY" \
-H "Content-Type: application/json" \
--data '{ "urls": {"inverted": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/inverted.jpg", "algebra": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/algebra.jpg"},"formats":["latex_simplified"] }'
import requests
import json
base_url = "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/"
r = requests.post(
"https://api.mathpix.com/v3/batch",
json={
"urls": {
"algebra": base_url + "algebra.jpg",
"inverted": base_url + "inverted.jpg"
},
"formats": ["latex_simplified"]
},
headers={
"app_id": "APP_ID",
"app_key": "APP_KEY",
"content-type": "application/json"
},
timeout=30
)
reply = r.json()
assert "batch_id" in reply
The response to the batch is a positive integer value for
batch_id.
{
"batch_id": "17"
}
The response to GET /v3/batch/17 is below when the batch has completed. Before completion the "results" field may be empty or contain only one of the two results.
{
"keys": ["algebra", "inverted"],
"results": {
"algebra": {
"detection_list": [],
"detection_map": {
"contains_chart": 0,
"contains_diagram": 0,
"contains_geometry": 0,
"contains_graph": 0,
"contains_table": 0,
"is_inverted": 0,
"is_not_math": 0,
"is_printed": 0
},
"latex_simplified": "12 + 5 x - 8 = 12 x - 10",
"latex_confidence": 0.99640350138238,
"position": {
"height": 208,
"top_left_x": 0,
"top_left_y": 0,
"width": 1380
}
},
"inverted": {
"detection_list": ["is_inverted", "is_printed"],
"detection_map": {
"contains_chart": 0,
"contains_diagram": 0,
"contains_geometry": 0,
"contains_graph": 0,
"contains_table": 0,
"is_inverted": 1,
"is_not_math": 0,
"is_printed": 1
},
"latex_simplified": "x ^ { 2 } + y ^ { 2 } = 9",
"latex_confidence": 0.99982263230866,
"position": {
"height": 170,
"top_left_x": 48,
"top_left_y": 85,
"width": 544
}
}
}
}
POST api.mathpix.com/v3/batch
The Mathpix API supports processing multiple equation images
in a single POST request to a different endpoint: /v3/batch.
The request body may contain any /v3/latex parameters except src and
must also contain a urls parameter.
The request may also contain an additonal callback
parameter to receive results after all the images
in the batch have been processed.
| Parameter | Type | Description |
|---|---|---|
| urls | object | key-value for each image in the batch where the value may be a string url or an object containing a url and image-specific options such as region and formats. |
| ocr_behavior (optional) | string | text for processing like v3/text or the default latex for processing like v3/latex |
| callback (optional) | object | description of where to send the batch results. Callback object |
The response contains only a unique batch_id value.
Even if the request includes a callback, there is no guarantee
the callback will run successfuly (because of a transient network failure,
for example). The preferred approach is to wait an appropriate length of time
(about one second for every five images in the batch) and then
do a GET on /v3/batch/:id where :id is the batch_id value.
The GET request must contain the same app_id and app_key headers
as the POST to /v3/batch.
The GET response has the following fields:
| Field | Type | Description |
|---|---|---|
| keys | string[] | all the url keys present in the originating batch request |
| results | object | an OCR result for each key that has been processed |
Process images as a batch with v3/text behavior
The ocr_behavior param can be set to text to enable images to be processed with v3/text behavior.
As with batch, all params can either be set at the top level or set individually.
Setting
ocr_behaviorand otherv3/textparams at the top level
{
"urls": {
"inverted": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/inverted.jpg",
"algebra": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/algebra.jpg"
},
"ocr_behavior": "text",
"formats": ["text", "html", "data"],
"data_options": { "include_asciimath": true }
}
Setting
ocr_behaviorand otherv3/textparams individually.
{
"urls": {
"inverted": {
"url": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/inverted.jpg",
"ocr_behavior": "text",
"formats": ["text", "html", "data"],
"data_options": { "include_asciimath": true }
},
"algebra": {
"url": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/algebra.jpg",
"ocr_behavior": "text",
"formats": ["text", "html", "data"],
"data_options": { "include_asciimath": true }
}
}
}
Make a batch request with
v3/textbehavior.
curl -X POST https://api.mathpix.com/v3/batch \
-H "app_id: APP_ID" \
-H "app_key: APP_KEY" \
-H "Content-Type: application/json" \
--data-raw '{
"urls": {
"inverted": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/inverted.jpg",
"algebra": "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/algebra.jpg"
},
"ocr_behavior": "text",
"formats": ["text", "html", "data"],
"data_options": { "include_asciimath": true }
}'
import requests
import json
base_url = "https://raw.githubusercontent.com/Mathpix/api-examples/master/images/"
r = requests.post(
"https://api.mathpix.com/v3/batch",
json={
"urls": {
"algebra": base_url + "algebra.jpg",
"inverted": base_url + "inverted.jpg"
},
"ocr_behavior": "text",
"formats": ["text", "html", "data"],
"data_options": { "include_asciimath": True }
},
headers={
"app_id": "APP_ID",
"app_key": "APP_KEY",
"content-type": "application/json"
},
timeout=30
)
reply = r.json()
assert "batch_id" in reply
The response to the batch is a positive integer value for
batch_id.
{
"batch_id": "17"
}
The response to GET /v3/batch/17 is below when the batch has completed. Before completion the "results" field may be empty or contain only one of the two results.
{
"keys": ["inverted", "algebra"],
"results": {
"inverted": {
"request_id": "2022_11_14_f985002323de848eb848g",
"version": "RSK-M104",
"image_width": 676,
"image_height": 340,
"is_printed": true,
"is_handwritten": false,
"auto_rotate_confidence": 0.0008788120718712378,
"auto_rotate_degrees": 0,
"confidence": 1,
"confidence_rate": 1,
"text": "\\( x^{2}+y^{2}=9 \\)",
"html": "<div><span class=\"math-inline \">\n<asciimath style=\"display: none;\">x^(2)+y^(2)=9</asciimath></span></div>\n",
"data": [
{
"type": "asciimath",
"value": "x^(2)+y^(2)=9"
}
]
},
"algebra": {
"request_id": "2022_11_14_f985002323de848eb848g",
"version": "RSK-M104",
"image_width": 1381,
"image_height": 209,
"is_printed": false,
"is_handwritten": true,
"auto_rotate_confidence": 0,
"auto_rotate_degrees": 0,
"confidence": 1,
"confidence_rate": 1,
"text": "\\( 12+5 x-8=12 x-10 \\)",
"html": "<div><span class=\"math-inline \">\n<asciimath style=\"display: none;\">12+5x-8=12 x-10</asciimath></span></div>\n",
"data": [
{
"type": "asciimath",
"value": "12+5x-8=12 x-10"
}
]
}
}
}
Callback object
| Field | Type | Description |
|---|---|---|
| post | string | url to post results |
| reply (optional) | object | data to send in reply to batch POST |
| body (optional) | object | data to send with results |
| headers (optional) | object | headers to use when posting results |
Supported image types
Mathpix supports image types compatible with OpenCV, including:
- JPEG files - _.jpeg, _.jpg, *.jpe
- Portable Network Graphics - *.png
- Windows bitmaps - _.bmp, _.dib
- JPEG 2000 files - *.jp2
- WebP - *.webp
- Portable image format - _.pbm, _.pgm, _.ppm _.pxm, *.pnm
- PFM files - *.pfm
- Sun rasters - _.sr, _.ras
- TIFF files - _.tiff, _.tif
- OpenEXR Image files - *.exr
- Radiance HDR - _.hdr, _.pic
- Raster and Vector geospatial data supported by GDAL
Error handling
All requests will return error and error_info fields
if an argument is missing or incorrect, or if some problem happens
while processing the request. The error field contains an en-us
string describing the error. The error_info field contains
an object providing programmatic information.
Error info object
| Field | Type | Description |
|---|---|---|
| id | string | specifies the error id (see below) |
| message | string | error message |
| detail (optional) | object | Additional error info |
Error id strings
| Id | Description | Detail fields | HTTP Status |
|---|---|---|---|
| http_unauthorized | Invalid credentials | 401 | |
| http_max_requests | Too many requests | count | 429 |
| json_syntax | JSON syntax error | 200 | |
| image_missing | Missing URL in request body | 200 | |
| image_download_error | Error downloading image | url | 200 |
| image_decode_error | Cannot decode the image data | 200 | |
| image_no_content | No content found in image | 200 | |
| image_not_supported | Image is not math or text | 200 | |
| image_max_size | Image is too large to process | 200 | |
| strokes_missing | Missing strokes in request body | 200 | |
| strokes_syntax_error | Incorrect JSON or strokes format | 200 | |
| strokes_no_content | No content found in strokes | 200 | |
| opts_bad_callback | Bad callback field(s) | post?, reply?, batch_id? | 200 |
| opts_unknown_ocr | Unknown ocr option(s) | ocr | 200 |
| opts_unknown_format | Unknown format option(s) | formats | 200 |
| opts_number_required | Option must be a number | name,value | 200 |
| opts_value_out_of_range | Value not in accepted range | name,value | 200 |
| pdf_encrypted | PDF is encrypted and not readable | 200 | |
| pdf_unknown_id | PDF ID expired or isn't | 200 | |
| pdf_missing | Request sent without url field | 200 | |
| pdf_page_limit_exceeded | PDF exceeds maximum page limit | 200 | |
| math_confidence | Low confidence | 200 | |
| math_syntax | Unrecognized math | 200 | |
| batch_unknown_id | Unknown batch id | batch_id | 200 |
| sys_exception | Server error | 200 | |
| sys_request_too_large | Max request size is 5mb for images and 512kb for strokes | 200 |
Privacy
Example of a request with the extra privacy setting:
{
"metadata": {
"improve_mathpix": false
}
}
By default we make images accessible to our QA team so that we can make improvements.
We also provide an extra privacy option which ensures that no image data or derived information is ever persisted to disk, and no data is available to Mathpix's QA team (we still track the request and how long the request took to complete). Simply add a metadata object to the main request body with the improve_mathpix field set to false (by default it is true). Note that this option means that images and results will not be accessible via our dashboard (accounts.mathpix.com/ocr-api).
Long division
Response for image on the left side:
{
"detection_map": {
"contains_chart": 0,
"contains_diagram": 0,
"contains_geometry": 0,
"contains_graph": 0,
"contains_table": 0,
"is_inverted": 0,
"is_not_math": 0,
"is_printed": 1
},
"latex_normal": "8 \\longdiv { 7200 }"
}
We use the special markup \longdiv to represent long division; it is the only nonvalid Latex markup we return. Long division is used much like \sqrt which is visually similar.
Latency considerations
The biggest source of latency is image uploads. The speed of a response from Mathpix API servers is roughly proportional to the size of the image. Try to use images under 100kb for maximum speeds. JPEG compression and image downsizing are recommended to ensure lowest possible latencies.
Supported math commands
Mathpix can generate any of the following LaTeX commands:
| \# | \$ | \% | \& | \AA |
| \Delta | \Gamma | \Im | \Lambda | \Leftarrow |
| \Leftrightarrow | \Longleftarrow | \Longleftrightarrow | \Longrightarrow | \Omega |
| \Perp | \Phi | \Pi | \Psi | \Re |
| \Rightarrow | \S | \Sigma | \Theta | \Upsilon |
| \Varangle | \Vdash | \Xi | \\ | \aleph |
| \alpha | \angle | \approx | \asymp | \atop |
| \backslash | \because | \begin | \beta | \beth |
| \bigcap | \bigcirc | \bigcup | \bigodot | \bigoplus |
| \bigotimes | \biguplus | \bigvee | \bigwedge | \boldsymbol |
| \bot | \bowtie | \breve | \bullet | \cap |
| \cdot | \cdots | \check | \chi | \circ |
| \circlearrowleft | \circlearrowright | \circledast | \cline | \complement |
| \cong | \coprod | \cup | \curlyvee | \curlywedge |
| \curvearrowleft | \curvearrowright | \dagger | \dashv | \dddot |
| \ddot | \ddots | \delta | \diamond | \div |
| \dot | \doteq | \dots | \downarrow | \ell |
| \emptyset | \end | \epsilon | \equiv | \eta |
| \exists | \fallingdotseq | \forall | \frac | \frown |
| \gamma | \geq | \geqq | \geqslant | \gg |
| \ggg | \gtrless | \gtrsim | \hat | \hbar |
| \hline | \hookleftarrow | \hookrightarrow | \imath | \in |
| \infty | \int | \iota | \jmath | \kappa |
| \lambda | \langle | \lceil | \ldots | \leadsto |
| \leftarrow | \leftleftarrows | \leftrightarrow | \leftrightarrows | \leftrightharpoons |
| \leq | \leqq | \leqslant | \lessdot | \lessgtr |
| \lesssim | \lfloor | \ll | \llbracket | \llcorner |
| \lll | \longdiv | \longleftarrow | \longleftrightarrow | \longmapsto |
| \longrightarrow | \lrcorner | \ltimes | \mapsto | \mathbb |
| \mathbf | \mathcal | \mathfrak | \mathrm | \mathscr |
| \mho | \models | \mp | \mu | \multicolumn |
| \multimap | \multirow | \nVdash | \nabla | \nearrow |
| \neg | \neq | \newline | \nexists | \ni |
| \nmid | \not | \notin | \nprec | \npreceq |
| \nsim | \nsubseteq | \nsucc | \nsucceq | \nsupseteq |
| \nu | \nvdash | \nwarrow | \odot | \oiiint |
| \oiint | \oint | \omega | \ominus | \operatorname |
| \oplus | \oslash | \otimes | \overbrace | \overleftarrow |
| \overleftrightarrow | \overline | \parallel | \partial | \perp |
| \phi | \pi | \pitchfork | \pm | \prec |
| \preccurlyeq | \preceq | \precsim | \prime | \prod |
| \propto | \psi | \qquad | \quad | \rangle |
| \rceil | \rfloor | \rho | \rightarrow | \rightleftarrows |
| \rightleftharpoons | \rightrightarrows | \rightsquigarrow | \risingdotseq | \rrbracket |
| \rtimes | \searrow | \sigma | \sim | \simeq |
| \smile | \sqcap | \sqcup | \sqrt | \sqsubset |
| \sqsubseteq | \sqsupset | \sqsupseteq | \square | \stackrel |
| \star | \subset | \subseteq | \subsetneq | \succ |
| \succcurlyeq | \succeq | \succsim | \sum | \supset |
| \supseteq | \supseteqq | \supsetneq | \supsetneqq | \swarrow |
| \tau | \textrm | \therefore | \theta | \tilde |
| \times | \top | \triangle | \triangleleft | \triangleq |
| \triangleright | \underbrace | \underline | \underset | \unlhd |
| \unrhd | \uparrow | \uplus | \vDash | \varepsilon |
| \varliminf | \varlimsup | \varnothing | \varphi | \varpi |
| \varrho | \varsigma | \varsubsetneqq | \vartheta | \vdash |
| \vdots | \vec | \vee | \wedge | \widehat |
| \widetilde | \wp | \xi | \zeta | \{ |
| \| | \} |